
Numeca is a Belgian-based software company providing high-fidelity computational fluid dynamic (CFD) tools (www.numeca.com). With roughly 120 employees and 70 software developers, the company’s Fine/Turbo software product - a structured, multi-block, multi-grid CFD solver targeting the turbomachinery industry - has more than 2,000 users in companies such as Honeywell and multiple supercomputing centers.
Working with Oak Ridge National Laboratory, the software development team wanted to accelerate the code on the Titan supercomputer while maintaining portability on a code that has been developed for more than 20 years.
“The target platform was Titan at Oak Ridge Leadership Computing Facility, but we were also interested in doing a general port which could be sold to customers as a commercial product,” said David Gutzwiller of Numeca.
Challenge
According to Gutzwiller, there were numerous challenges in accelerating Fine/Turbo, including:
- Development time: Only a few person-months were allocated for adding GPU acceleration into the code, which required a portable approach with minimal developer effort.
- Code maintenance: Fine/Turbo is in constant development by a team of engineers. The GPU acceleration should not interfere with the ability of other developers to modify and commit changes or bug fixes. Also, there should be no duplicate sources for easy maintenance.
- Code portability: Many Fine/Turbo customers still use traditional homogenous CPU systems. The GPU acceleration work should be portable on those systems.
“Writing and maintaining a code base of this size is a challenge in itself, and requires a huge outlay of effort to make large-scale changes,” he said.
“We were on a tight schedule, and we needed high accuracy for the end product, so there was little room for error.”
Solution
Leveraging OpenACC to repurpose the code, Gutzwiller’s team followed the host-accelerator paradigm. Thirty of the most computationally expensive routines were targeted for acceleration. Host processes on the CPU manage the computation, offloading the high-value routines to the GPU for improved execution time.
“OpenACC enabled us to target and prepare routines for GPU acceleration without rewriting them which helps to minimize potential errors,” said Gutzwiller. OpenACC also enabled the team to prepare the code to run on many different types of supercomputers, enabling portability across all customer environments.
Results
With OpenACC, key routines often saw 10x speed-up or more compared to highly tuned CPU implementation. Typical configurations have shown a global speedup of about 2x, when 16 CPUs are running on the OLCF Titan system (16 core AMD CPU + 1 NVIDIA Tesla K20 per node), depending on the model configuration and mesh size. The best observed speedup on Titan is 2.5x with a very clean, well-balanced model. Because the 30 routines make up roughly 70 percent of the run time, 1.75-2.5x speed-up surpassed expectations. Total time spent on accelerating Fine/Turbo with OpenACC was about five person-months.
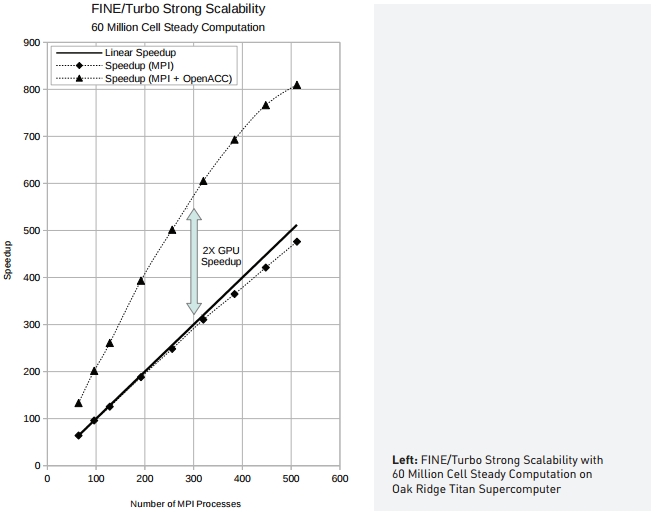
GPU acceleration with OpenACC resulted in a large improvement in time-to-solution, enabling a much faster engineering design cycle, which, according to Gutzwiller, is very appealing to both researchers and industrial customers. The accelerated code will enable customers to cut costs significantly, while speeding time to market with new products. “On a supercomputer, time is the biggest cost,” he said. “With the acceleration, users spend half the hours to get the same results.”
Gutzwiller believes the majority of Numeca’s customers will leverage the accelerated code moving forward. He plans to expand instrumentation with OpenACC further into other Fine/Turbo modules and Numeca tools. “Most of our customers have GPUs,” he said. “Once we get to all our customers, there’s no telling how many will use it and reap the benefits.”