Evaluating the Performance of OpenACC in GCC
In this blog, we will be discussing the history of the OpenACC GCC implementation, its availability, and enhancements to OpenACC support in GCC. You will also learn about a recent project to assess and improve the performance of codes compiled with GCC’s OpenACC support.
The Role of OpenACC
A scalar optimizing compiler has a really good day when it gets an optimization that boosts performance by 5%. Scalar architectures have (relatively) limited opportunities for optimization and scalar optimizing compilers have decades of theory and implementation effort supporting them. The landscape is different for compilers targeting parallel and vector hardware (often called “restructuring compilers”) such as that possessed by GPUs. Effectively used, parallel and vector hardware provide speedups that easily dwarf scalar optimizers’ best days. “Effectively used” is the key phrase. Parallel hardware deployed effectively provides speedup measured on logarithmic scales. As frustrated programmers are well aware, parallel hardware ineffectively deployed provides negative speedups (i.e. slowdowns) – particularly frustrating on a system where speedups of 10-100x are expected.
The OpenACC API defines a collection of directives and routines developed to help soothe frustrated programmers. Using OpenACC directives, a programmer helps a compiler uncover and schedule parallelism particularly on GPUs which possess a rich variety of parallel opportunities. PGI has been an early leader of OpenACC development, and the PGI compiler is the most mature implementation of OpenACC. GCC, on the other hand, is a relative newcomer to OpenACC.

OpenACC and GCC
OpenACC support in GCC was first released in the spring of 2015. This release was based on GCC 5.0 and the OpenACC 2.0a specification and was incomplete and buggy. Since then Mentor has continued to extend and enhance the OpenACC coverage, so that it now covers most of the OpenACC 2.5 spec and is a solid implementation. For details on current coverage see: https://gcc.gnu.org/wiki/OpenACC#openacc-gcc-8-branch:_OpenACC_development_branch.
|
While the GCC implementation is definitely solid, compilers — particularly restructuring compilers — are extremely complex pieces of software. Programming languages permit numerous ways of expressing computations, and there are always multiple ways of implementing a computation on a target. As a result, conventional wisdom holds that it takes years and compilation of many millions of lines of input code to season a scalar compiler to maturity. The OpenACC implementation in GCC is solid, but it has had nowhere near that much seasoning. |
While that conventional wisdom has been born out many times for scalar optimizing compilers, as the introduction points out restructuring compilers are very different beasts. In particular, given that the primary optimization for restructuring compilers is exploiting parallelism and that parallelism provides orders-of-magnitude speedups, it is not outrageous to believe that a directive-based compiler can mature much faster than scalar optimizing compilers.
The Experiment
To test that hypothesis, and also to get a measure of how seasoned GCC’s OpenACC is, Mentor experimented by comparing the performance of OpenACC in GCC to that in PGI and investigating the sources of any differences. Understanding the source of the differences can help guide development of new compilers, as well as provide insight into where GCC’s implementation of OpenACC could be improved. A large number of small differences would indicate that seasoning is as important for restructuring compilers as it is for scalar optimizing compilers — kaizen is a process that takes time. A small number of large differences would imply a different scenario: a few important optimizations which had been overlooked in the implementation.
To perform the experiment, Mentor needed to choose an application to compile and an input data set on which to run the compiled code. Given the hypothesis under test, the ideal application would be one which executed considerably faster when compiled with PGI than when compiled with GCC. For the results to have the broadest applicability and impact, it would also help if the application were representative of a large class of codes. And of course, it would be good if the application itself were one that is commonly run.
After investigating several possibilities, Mentor choose the application LSDalton. Details of LSDalton and the experiment follow.
LSDalton
The OpenACC version of LSDalton is a widely-used linear-scaling HF and DFT code suitable for large quantum chemistry codes and was developed by a research team at Aarhus University in Denmark. LSDalton was chosen to measure the relative performance of the two compilers. The data set used was a modified version of the decrimp2_restart, a production ready algorithm that uses OpenACC.
A small number of source code modifications were required:
1. Conversion of all kernel regions to equivalent parallel regions. The intent was the test the OpenACC support in the compiler, not the compiler’s auto-vectorization capability.
2. Replaced calls to BLAS routines – specifically dgemm and dgemv—with calls to the generic equivalent Fortran source routine. The goal was to measure the effectiveness of the compiler, not the efficiency of hand-coded libraries.
3. Addition of OpenACC directives to enact parallel loop and region calls to the generic dgemm and dgemv routines.
4. Hand implementation of auxiliary induction variable substitution on a few loops that caused problems when compiled with the PGI compiler.
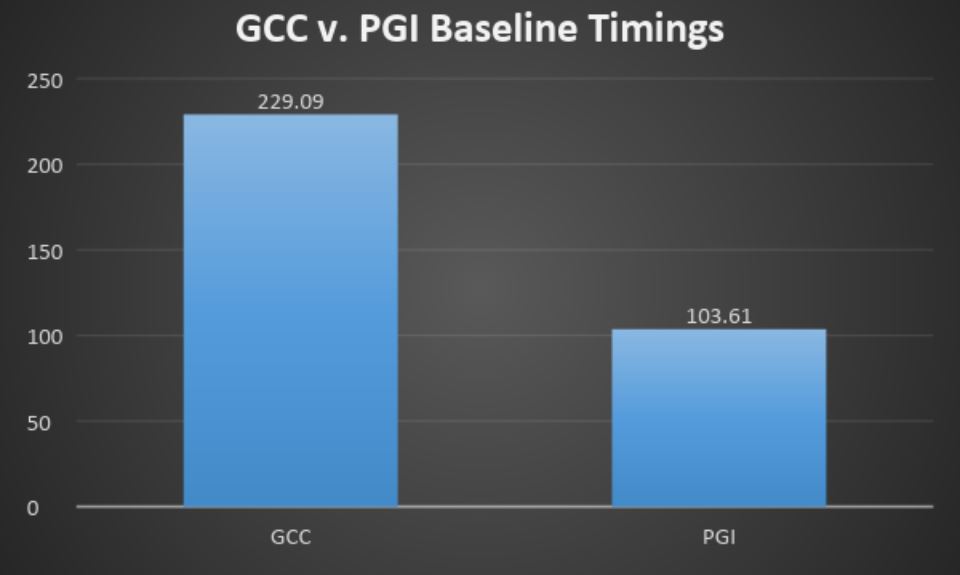
Baseline Timings
The OpenACC version of LSDalton when compiled with GCC for NVIDIA GPUs ran considerably slower than the same source code compiled with PGI. Details on compiler versions, compiler options, benchmark versions, and hardware are provided at the end of this post.
Shampoo, Rinse, Repeat
We undertook the standard cycle of profile, analyze, and change, and found results that were different than what you typically find in these exercises. They provide a useful lesson in the implementation of large codes as well as subtleties involved in exploiting highly parallel systems.
Unwelcome Visitor
The first observation was that the GCC version was being invoked with the “-ffloat-store” option. This option causes GCC to store floating point values as soon as they are computed and to fetch them from memory whenever needed. This was obviously causing a significant slowdown in the execution time. The usual cause for an option like that (other than the occasional naïve user) is typically a compiler bug which the user hides or works around by enabling an option that thwarts optimization. That in fact turned out to be the case here. When we removed the option, LSDalton compiled under GCC generated incorrect results. Our analysis pointed to a compiler code generation error. Interestingly enough, the problem occurred in only one small routine out of the entire LSDalton application. Had the option been enabled in only that routine, correct execution could have been achieved with little performance loss. Regardless, we fixed the underlying compiler bug, allowing the option to be disabled across the entire program with a significant gain in performance. This functionality is available in GCC 8.1.
%20vs%2C%20PGI.JPG)
Memory Contention in Parallel Regions
The next item turned out to be the way in which GCC launched parallel regions. When initiating parallelism from the host, GCC would place all the appropriate parameters that needed to be passed to the region in global memory, then pass a pointer to that memory to each of the instantiated threads. The threads would then immediately read the values from global memory, creating (not surprisingly) a huge amount of contention. We implemented a different mechanism: passing the values directly to the threads as part of the instantiation process. The difference was significant: the running time was reduced by 15%. Support for this improvement is available by downloading the GCC 8 OpenACC branch.
%20vs.%20PGI.JPG)
With these changes, the OpenACC version of LSDalton when compiled with GCC takes 106.5 seconds to execute. The same version compiled with PGI on the same data set and hardware takes 103.61 seconds to execute. The performance of GCC and PGI are essentially the same, and given that PGI is a very good, very mature compiler, it probably means that GCC is doing as well as possible.
Not unexpectedly, the improvements made to GCC for LSDalton also benefited other programs. Mentor showed a 3% performance improvement across its internal performance regression suite. Individual applications in some instances did much better — Cloverleaf, for instance, improved by over 10% and many of the SPEC benchmarks improved by 6%.
Conclusions
It is always dangerous to draw conclusions from a small sample size, and a sample size of one is just about as small as you can get. However, there are some interesting conclusions in this case. Two problems caused a very large difference in performance (over 100% slower). While the root cause of the larger contributor was a compiler bug, it also reflects a natural user reaction to apply brute force solutions when encountering problems. Achieving performance on any architecture, but particularly a parallel architecture, requires tuning. Architectural interactions are so complex that no one can predict exactly how any given code fragment will perform; the only way to truly tell is to try it. The second problem illustrates exactly those complexities. The difference between passing a pointer to parallel threads versus passing values directly would be, on first examination, predicted by most to have no significant performance differences. It is fairly easy to forget that apparently insignificant differences can become very significant when multiplied by the effects of hundreds and thousands of threads.
For the Technically Motivated
For those interested in the technical details, the hardware used was an NVIDIA® GeForce® GTX 1080 with 8113 MiB Ram driven by an Intel® Xeon® CPU E5-2640 v4 @2.10 GHz with 32 GB of RAM under Ubuntu 14.04g. The system was running CUDA® 8.0.44. A development snapshot based on version 1.3 was used for LSDalton. The PGI® compiler was version 17.9-0 64-bit target on x86-64 Linux -tp haswell; the gcc version used was (obviously) an internal version under development. PGI compiler flags used were “-ta=host,tesla:cc60 -lnvidia-fatbinaryloader –lcuda”. GCC was invoked with ”-fopenacc –lcuda”.
If you’re interested in getting a copy of the GCC compiler, contact Pesh Gala at kalpesh_gala@mentor.com. The PGI compiler is freely downloadable from www.pgicompilers.com/community.
Author
